Les outils de supervision actuels, en constante amélioration, deviennent indispensables pour surveiller des systèmes toujours plus complexes, des applications critiques, des technologies innovantes …
Cette supervision se révèle très efficace en temps réel, mais ne convient que peu à une analyse continue des données systèmes et applicatives. La centralisation et l'exploitation des journaux d’évènements (logs) permettent de pallier ce besoin.
L’utilisation de la suite Elastic est une solution qui convient parfaitement à ce cas de figure.
“The Elastic Stack” (anciennement ELK) en détails :
- Beats : agents légers de collecte et de transfert de données
- Filebeat : agent dédié aux logs
- Logstash : agrégateur de logs, transforme puis transporte les logs vers un stockage
- Elasticsearch : moteur d’indexation et de recherche, destination finale de nos logs
- Kibana : interface de visualisation et d’analyse pour Elasticsearch
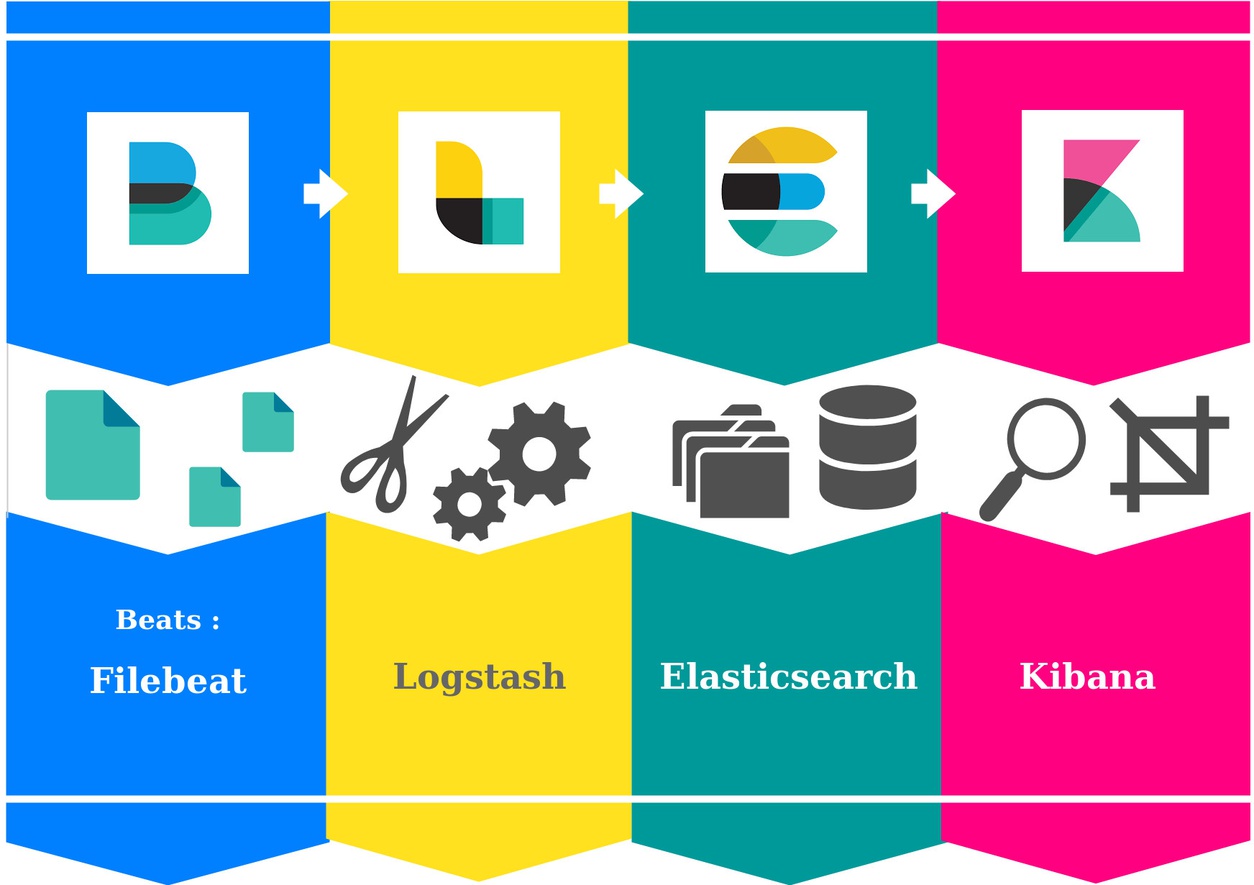
Logstash
Les deux éléments essentiels à la pipeline Logstash sont ses extrémités, une entrée et une sortie. En effet il faut pouvoir obtenir les informations, mais également savoir où les envoyer.
En entrée, Logstash récupère les données provenant de multiples sources (fichiers, syslogs, agents Beats,...).
En sortie, ces données peuvent tout autant être renvoyées sur des stockages divers, ici nous utiliserons Elasticsearch.
Entre ces deux étapes, la possibilité de filtrer, découper, désosser les logs offre un puissant traitement pré-indexation qui permettra par la suite de les analyser et les exploiter bien plus efficacement. Pourtant optionnelle, cette possibilité représente l’intérêt majeur de cet outil.
Filebeat
Les agents de collectes sont les abeilles ouvrières de la grande ruche qu’est la suite Elastic. Légers, rapides et efficaces, ils butinent les fichiers, récoltant les logs et les apportant à leur reine Logstash ou bien directement à Elasticsearch.
De plus, ils supportent également certaines fonctions de filtrage, certes plus rudimentaires que Logstash, mais très utile pour élaguer considérablement la masse de données à transporter.
Elasticsearch
Centre névralgique de la suite, Elasticsearch peut indexer d’immenses quantités de données, et surtout, permet d’effectuer sur celles-ci des recherches extrêmement poussées tout en conservant une précision et une rapidité d’exécution exemplaires.
Adapté aux besoins de chaque type / taille d’infrastructure, il convient à une utilisation cantonnée et solitaire tout en s’intégrant parfaitement à une architecture distribuée, scalable, et hautement disponible.
L’utilisation d’Elasticsearch, l’élaboration de requêtes et les résultats obtenus sont accessibles via des API RESTful et JSON mais aussi par l’intermédiaire de l’interface web Kibana.
Kibana
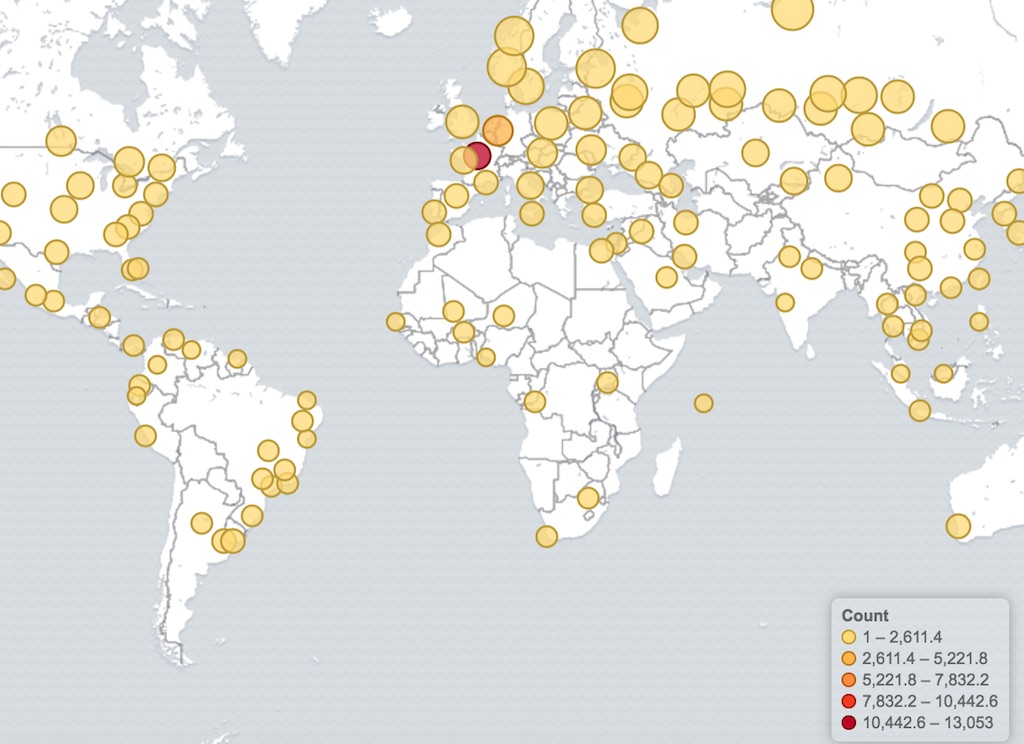
Cette interface interactive et paramétrable permet de visualiser les éléments stockés dans Elasticsearch. Allant de la simple valeur d’un unique document à des graphiques et histogrammes aux nombres de données quasi illimités, en passant par des représentations diverses telles que des nuages de mots ou des cartographies, les possibilités offertes par cet outil sont immenses.
L’ensemble de ces représentations peut être agencé sur des tableaux de bord, de façon à obtenir des vues complètes, concises ou détaillées.
Kibana inclut, comme mentionné précédemment, une section « Dev Tools » soit « Outils de développement » qui est extrêmement utile afin d’interagir directement sur les données stockées ou bien simplement pour tester de nouvelles requêtes.
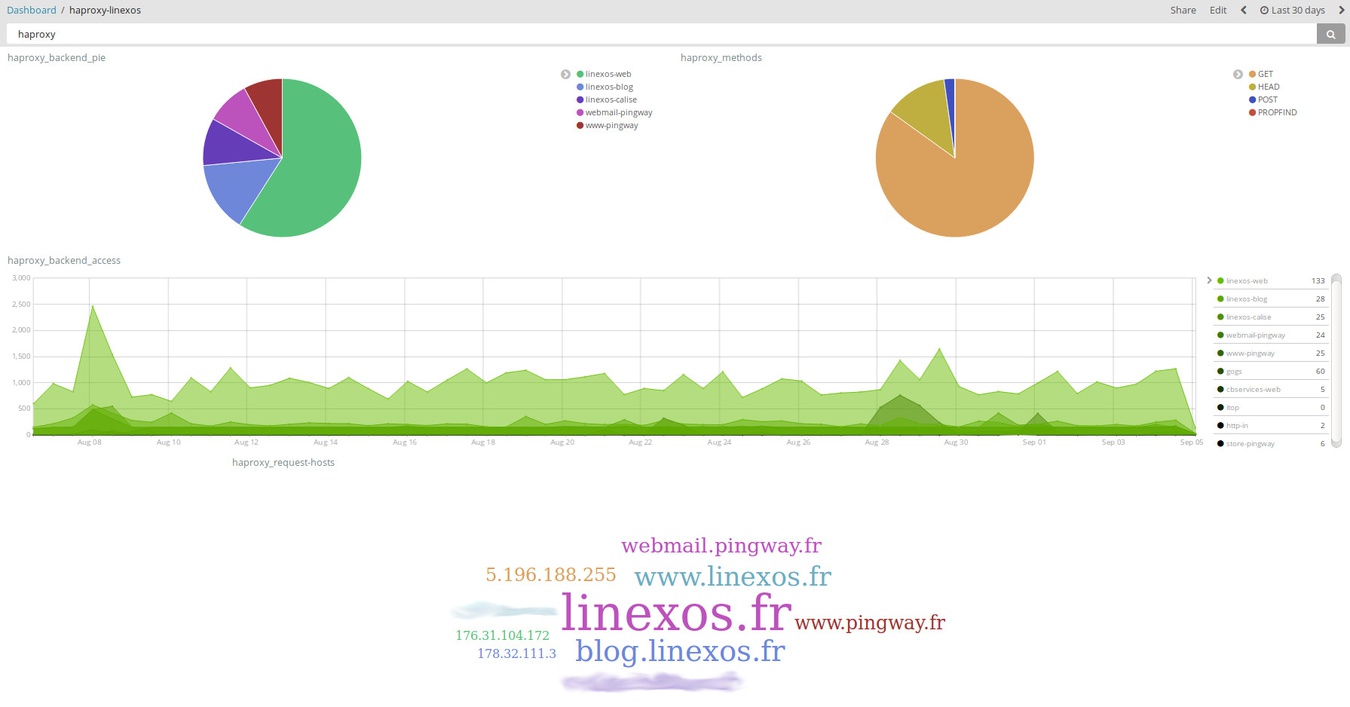
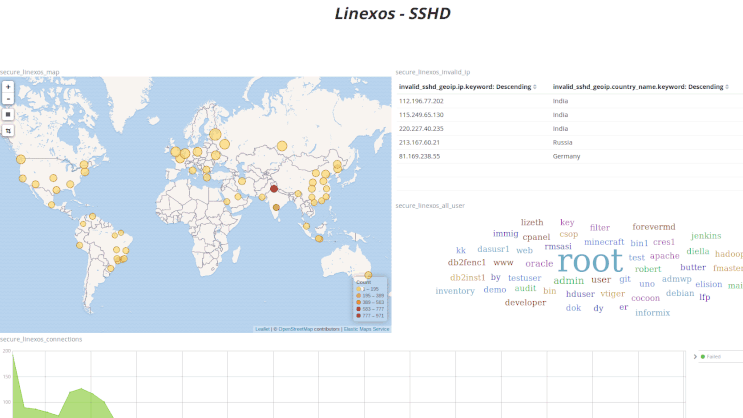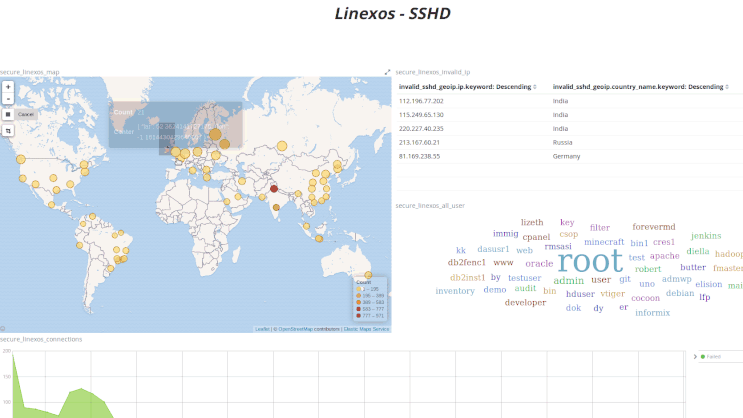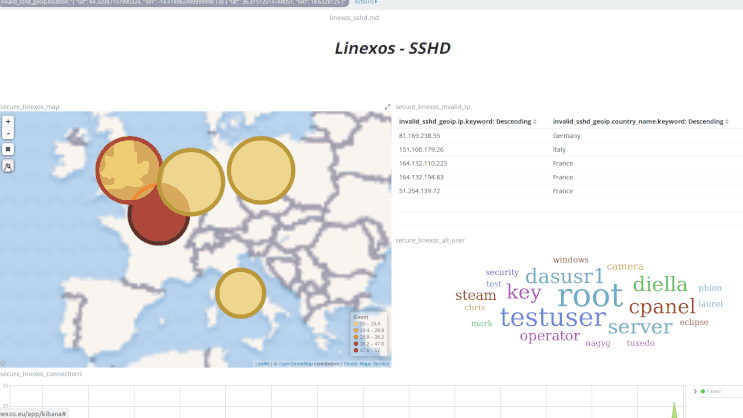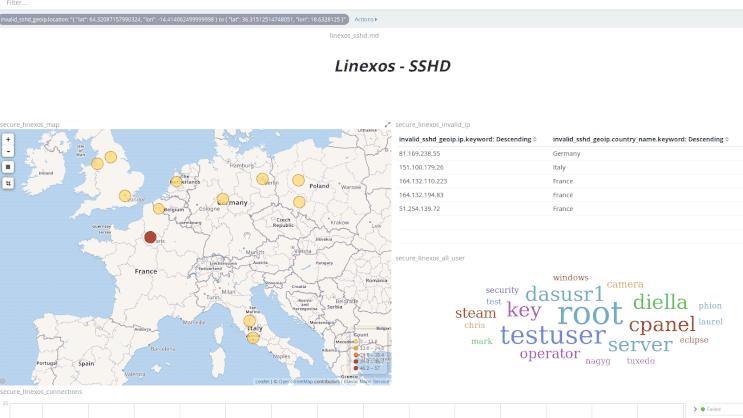
Ces tableaux de bords ( ci-dessus, à partir de logs HAProxy; ci dessous, à partir de logs de tentatives de connexion SSH) illustrent en partie les possibilités qu'offre Kibana en matière de visualisation.
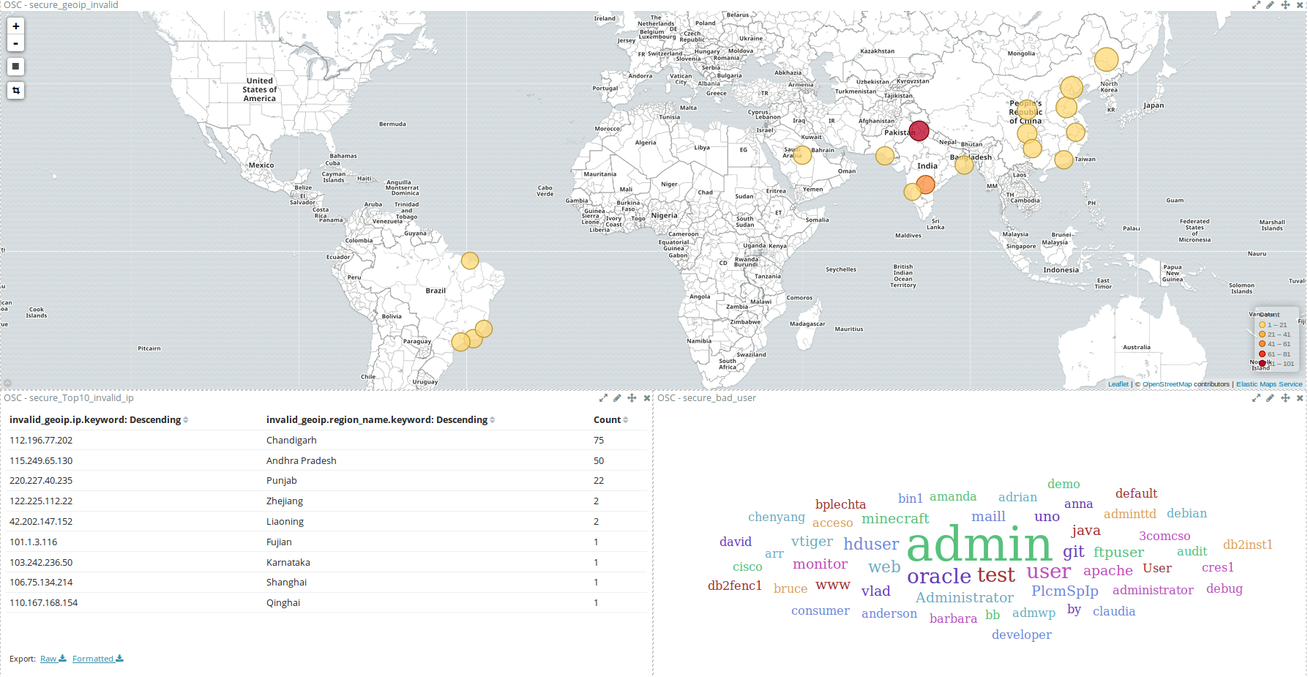
Pour en arriver à ces résultats, il faut d'abord créer les différents éléments (graphs, cartes, listes,...) à partir de recherches enregistrées ou d'index bruts, puis constituer les tableaux de bord avec ces éléments. Un même élément peut donc être réutilisé sur plusieurs tableaux de bord.
Après avoir pris en main le fonctionnement de Kibana, on peut approfondir l'exploitation de ces vues grâce à leur malléabilité : l'application de filtres à la volée permet, en une unique action, de resserer la visualisation aux seules données voulues.
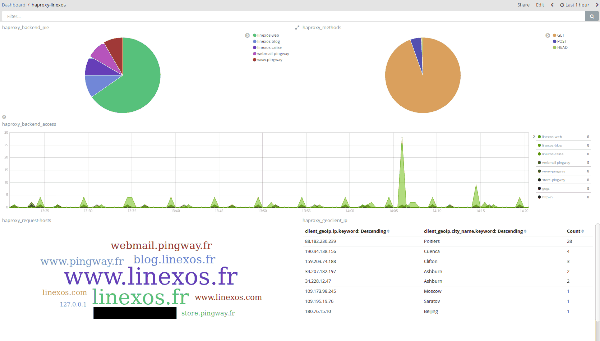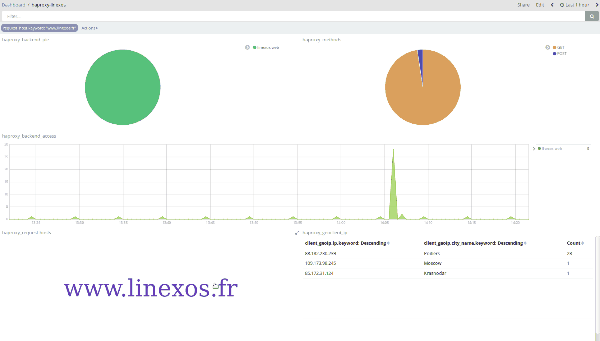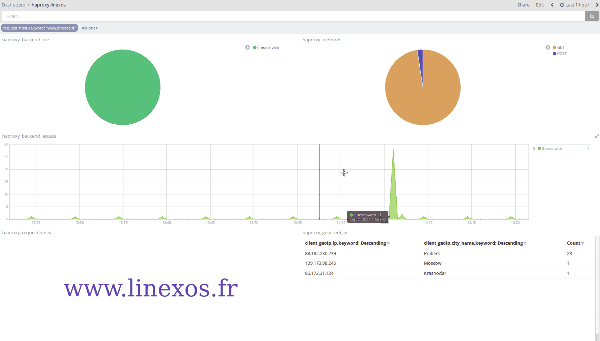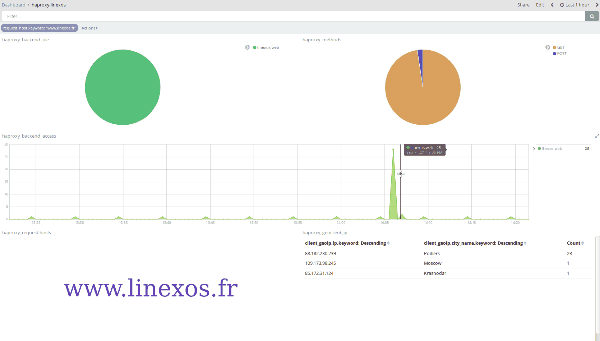
Ci-dessus, des logs HAProxy filtrés en un clic sur un élément du nuage de mots; ci-dessous des logs de connexions SSH filtrés géographiquement en traçant un rectangle sur la carte.
Avec Shinken
Transférer, par l'intermédiaire d'un module, les résultats des checks Shinken vers une base Elasticsearch permet de mettre à profit son potentiel de recherche et d’analyse afin d’exploiter plus profondément cette supervision, et d’obtenir des informations adaptées au reporting.
À l'inverse, en employant un plugin qui va pouvoir lire et effectuer des recherches sur les données indexées dans Elasticsearch, Shinken peut récupérer des informations difficiles à obtenir autrement. Ainsi on pourra y apposer les avantages de la supervision, avec par exemple la possibilité de notifier une alerte en fonction de conditions (seuils, termes, nombres,...).
Ces pratiques facilitent notamment la mise en place d'une supervision axée sécurité. Par exemple, en correlant l'analyse de logs de connexion avec des alertes de supervision, on peut mettre en évidence les éléments sensibles de notre infrastucture. Cela s'intègre parfaitement aux politiques de sécurité en vigueur, et peut même servir de socle à leurs élaborations si elles étaient inexistantes.
En amplifiant les capacités de chacun des deux outils, Shinken et la suite Elastic, cette double liaison engendre une fiabilisation et une consolidation de votre supervision, et pose les bases de l'hypervision métier.
