La mise en œuvre d'une supervision efficace n'est pas compliquée, avec un peu de méthode, et en faisant les choses dans l'ordre. Toute la réussite réside dans l'exploitation des données extraites des outils de monitoring.
L'objectif de cet article est de montrer, à travers un exemple concret, comment superviser efficacement vos applications, et comment valoriser votre outil de supervision.
Introduction
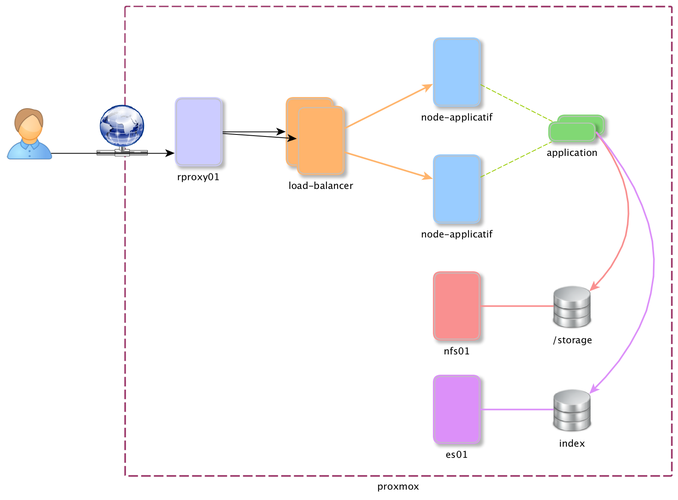
Pour cet article, nous allons prendre comme exemple une application web, fonctionnant dans un conteneur Docker orchestré par OpenShift. L'ensemble de l'infrastructure est virtualisée avec Proxmox.
Cette application dépend donc de plusieurs briques essentielles pour fonctionner et pour être disponible depuis l'extérieur, comme le montre le schéma ci-dessous.
Surveillance Système
Nous allons donc ajouter chacun de ces serveurs dans notre outil de supervision préféré, pour disposer, dans un premier temps, d'une surveillance système :
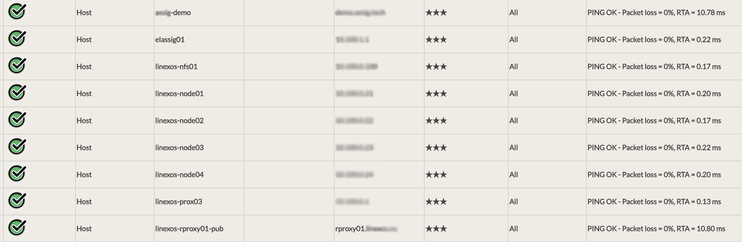
Les indicateurs systèmes nous permettront d'avoir une bonne visibilité sur les différentes métriques : mémoire, CPU, Disks, etc.
C'est pas mal, mais ça ne va pas nous aider beaucoup pour connaître l'état de fonctionnement de notre application !
Les services
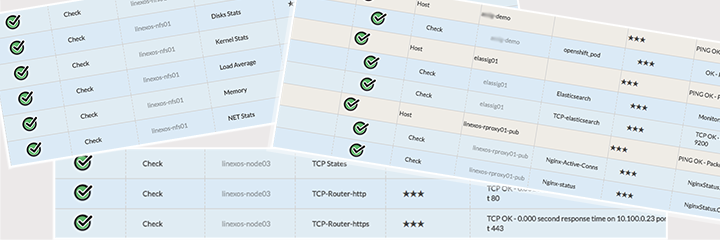
Continuons donc en ajoutant les briques "services" des différents éléments :
- nginx : http / https
- elasticsearch : taille des index, état de l'api, etc.
- openshift : état du conteneur (pod)
- etc.
Bien !
Nous connaissons maintenant l'état de nos serveurs, de nos services, et nous disposons également de métriques :
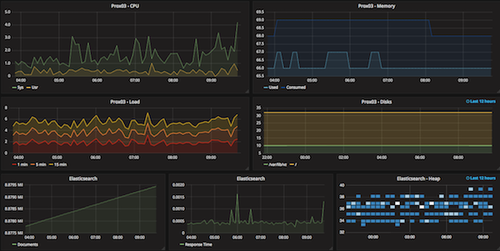
A ce stade, nous serons alerté en cas
- de perte d'un serveur
- de perte d'un service
- d'un dépassement de seuil
Les règles métiers
La dernière étape consiste à écrire des règles permettant de décrire cette application. L'objectif derrière cette étape, est de connaître à tout moment l'état de notre application, et également de connaître les impacts en cas de perte d'un des composants.
Autrement dit, ces règles devront répondre à ces questions :
- Est-ce que mon application est disponible ?
- Que se passe-t-il si tel ou tel élément devient indisponible ?
- De quoi est composé mon application ?
- Quel est le niveau de disponibilité de mon application ?
Pour répondre à ces questions, l'outil de supervision doit connaître les composants essentiels à la survie de notre applicaiton, et doit également prendre en compte les éventuelles fiabilisations mises en place (Haute Disponibilité).
Nous allons donc commencer par décrire notre cluster, et petit à petit remonter jusqu'à notre application.
Business Rules N°1 : Plateforme Proxmox
La première règle consiste à vérifier le bon fonctionnement de notre infrastructure de virtualisation, en ne prenant que l'essentiel, ce qui donne :
Proxmox03 = linexos-prox03 AND linexos-prox03/Disks
Cette règle simple, permet de s'assurer que l'hyperviseur est présent, et qu'il reste suffisamment d'espace disque pour les systèmes invités.
Business Rules N°2 : Plateforme Openshift
La seconde règle va concerner le cluster Openshift, qui se compose de plusieurs serveurs :
- 2 nodes applicatifs : les images Docker sont démarrées sur ces nodes en répartition de charge
- 2 nodes infra : ces nodes permettent l'exécution des Loadbalancers (nginx) et du docker-registry
- 1 node master : l'orchestrateur, l'API Openshift, la console d'administration Openshift
- 1 loadbalancer frontal : Service nginx public, permettant quelques filtrages, et permettant le reverse-proxy vers les bons loadbalancer openshift
Pour que le cluster soit considéré comme opérationnel, il faut donc qu'au moins un de chacun des composants soit actif :
Openshift = (linexos-node01 OR linexos-node02) AND (linexos-node03 OR linexos-node04) AND linexos-openshift01 AND linexos-rproxy01-pub/Nginx-status AND linexos-rproxy01-pub/Https
Cette règle, combinant des ET/OU nous donnera un état précis quant au fonctionnement du cluster Openshift, et pourra par la suite être réutilisée pour chacune des applications et conteneurs.
Business Rules N°3 : Datastore Openshift
La troisième règle va concerner les espaces de stockage utilisés par notre application. Cette application va à la fois lire et écrire des documents indexés dans elasticsearch, et va également enregistrer des fichiers plats dans un volume NFS.
Nous pouvons donc considérer que ces deux espaces de stockage peuvent être regroupés dans une règle "openshift-datastore" :
Openshift-datastore = elassig01/Elasticsearch AND elassig01/Disks AND linexos-nfs01/Disks
Cette règle pourra aussi être réutilisée pour chaque instance de cette application, voire pour d'autres applications s'appuyant sur le même fonctionnement.
Business Rules N°4 : Application / Container
La quatrième règle va concerner l'application elle-même. Cette application est capable de retourner un état de type "Health Check", ce qui va permettre d'en verifier le bon fonctionnement. Cette application est démarrée lorsqu'au moins un conteneur Docker est démarré.
App-Demo-Health = app-demo/Https AND app-demo/openshift_pod
Le check "Https" appelle une URL de type "Health Check" permettant de vérifier à la fois la connectivité avec l'application, et son état de fonctionnement interne.
Business Rules N°5 : Application : Consolidation
Cette dernière règle va en fait être une règle de consolidation de l'ensemble des règles précédentes. Elle va servir à disposer d'une règle globale reprenant l'ensemble des états indispensables au bon fonctionnement de notre application.
App-Demo = Proxmox03 AND Openshift AND Openshift-datastore AND App-Demo-Health
Ce qui, graphiquement, nous donnera :
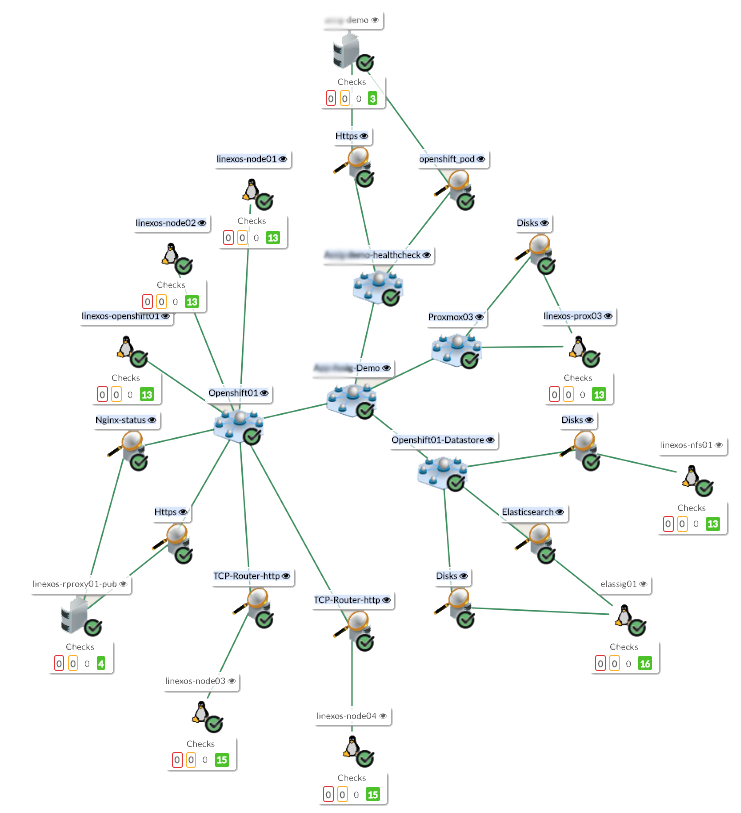
Excellent !
Nous avons maintenant une supervision fine pour notre application, qui va nous permettre :
- De connaître immédiatement les impacts en cas de perte de l'un des composants
- D'être alerté sur la cause en cas de problème
- D'alerter les bons contacts en fonction des problèmes
Notifications
Comme l'évoque le dernier point, il est effectivement possible, à travers cette règle métier, d'envoyer les notifications aux bons contacts, en fonction de la criticité, et en fonction de l'impact.
Voici quelques exemples :
Warning sur l'espace disque NFS
Impact : Aucun
Criticité : Sérieux
Qui : Administrateurs
Node01 Hors service
Impact : Aucun
Criticité : Léger
Qui : Support,Administrateurs
Rproxy / Nginx Arrêté
Impact : App-Demo
Criticité : Grave
Qui : Administrateurs, Responsable de production, Client
App-Demo-Healthcheck KO
Impact : App-Demo
Criticité : Grave
Qui : Support, Développeurs, Responsable de production, Client
Comme le montrent ces quelques exemples, il est très facile, avec ce type de règle, de mettre des contacts en face de chaque brique, et en face de chaque "étage". Ce système permettra également de mettre en place des escalades.
Les notifications seront efficaces, et le temps de résolution des incidents sera fortement diminué, du fait que la cause du problème sera toujours mise en avant.
Pour aller plus loin
Notre supervision active est opérationnelle, et apporte une vraie valeur ajoutée pour notre application. Ce qui nous manque, c'est une détection d'erreur ou de défaillance de l'application.
Si c'est un sujet difficile à aborder avec les outils de monitoring classiques, les outils de collecte et indexation de Logs seront vos alliés !
Il est en effet possible, et même fortement recommandé, de récolter les logs à tous les niveaux : Système, Service, Applicatif, LoadBalancer.
Le fait de récolter ces journaux, et surtout le fait de les indexer avec un outil digne de ce nom comme la stack Elastic, vous permettra :
- D'effectuer des recherches dans les logs en cas de problème
- De mettre en place des tableaux de bords liés à l'activité (KPI)
- De rapprocher les états issus du monitoring avec les métriques applicatives
Et pour aller encore plus loin, il est même possible, de mettre en place des plugins qui iront interroger les index, afin de surveiller des comportements applicatifs.
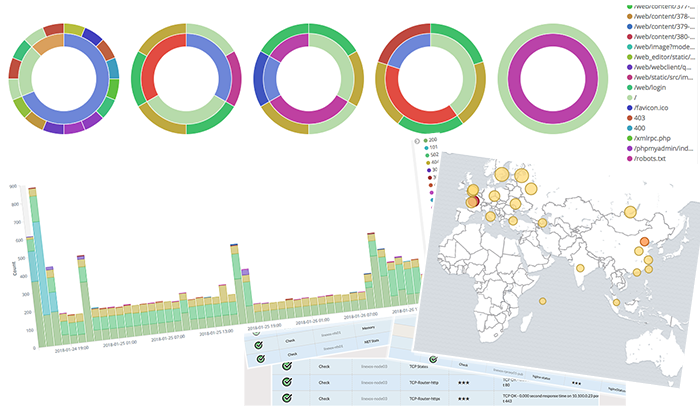
Reprenons notre exemple, voici le type de tableaux de bords que nous avons mis en place avec la stack Elastic :
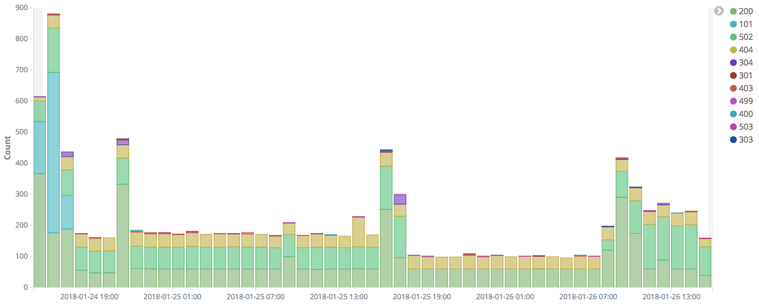
![]()
Ce type de Dashboard permet d'avoir des statistiques basées sur les éléments suivants :
- Temps de réponse des pages
- Code HTTP des requêtes
- URLs appelées
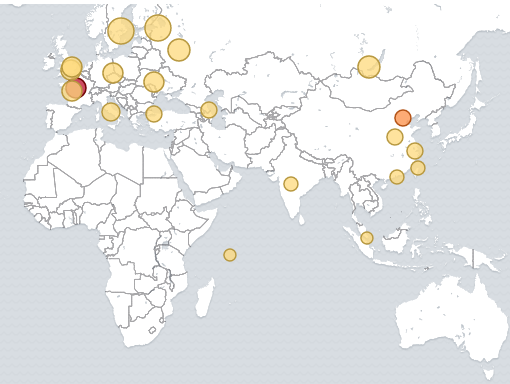
- Adresse IP des clients HTTP
- Géolocalisation des clients
Il est alors facile d'imaginer que l'on peut mettre en place des plugins, sur notre outil de supervision, qui nous retourneraient les résultats suivants :
- Nombre d'erreur 404 sur la dernière demie-heure
- Nombre d'erreur 500 sur les 10 dernières minutes
- Temps de rendu moyen des pages (status 200)
Et pour passer le cap du pseudo-machine learning, ou de potentiels risques, il est possible de mettre en place des alertes se basant sur :
- un seuil maximale de requêtes par IP (DDOS détection ?)
- un seuil maximale d'erreurs pour une même IP (tentative d'injection ?)
- etc.
Conclusion
Comme le montre cet article, les outils actuels, combinés, permettent d'aller très loin en matière de supervision.
Cette approche n'est pas la seule, mais elle est redoutablement efficace, et permet de garder une cohérence d'un bout à l'autre, en disposant de composants réutilisables et maintenables.
Pour plus d'infos : info@linexos.fr
