Une Infra DevOps Open Source ? C'est possible ça ? Et ça marche ? Ou c'est encore un truc de Barbus ?
Nous allons tenter, à travers une série d'articles, de répondre à toutes ces questions, et même plus...
Ce premier article a pour objectif de présenter l'architecture et de présenter chacune des briques utilisées.
Objectif de notre infrastructure
Notre infrastructure, devra permettre d'aider les développeurs dans leur quotidien, et devra également permettre de soulager la partie administration de systèmes, en étant agile, et sans pour autant compromettre la sécurité.
Voici une liste des points indispensables pour notre infrastructure DevOps :
- déploiement continu d'applications
- environnements prod, recette, etc.
- scalabilité sans compromis
- liberté du choix d'hébergeur (Hébergement public, OnPremise, Infogéré, IAAS, etc.)
- facilité de déploiement et de maintenabilité
- une interface Web pour la gestion de nos applications
Et bien sûr, de l'Open Source ! Pas seulement par principe ou par éthique, mais pour plus de souplesse, plus d'ouverture sur les outils connexes, etc.
Schéma fonctionnel
L'infrastructure reposera sur un hyperviseur pour la virtualisation, sur un orchestrateur pour les conteneurs, et sera composée d'un load-balancer publique, ainsi que de différents datastores.
Le schéma suivant montre à la fois l'organisation et les choix techniques sur lesquels reposeront notre système orienté DevOps :
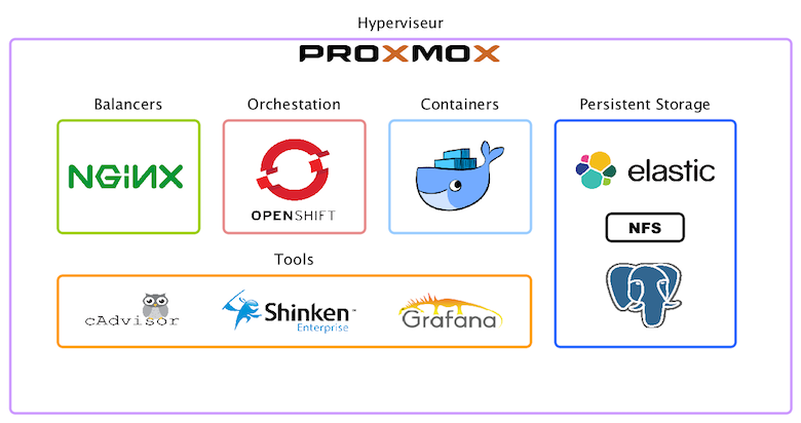
Détail des composants
Proxmox
Proxmox est une solution de virtualisation libre, basée sur KVM et de type "bare metal". Cet hyperviseur permet également de déployer des conteneurs LXC, mais que nous n'utiliserons pas dans notre cas. Cette solution est très complète, offrant une interface de configuration "Full Web", des fonctionnalités relativement simaires à VMware, elle propose également la gestion de cluster.
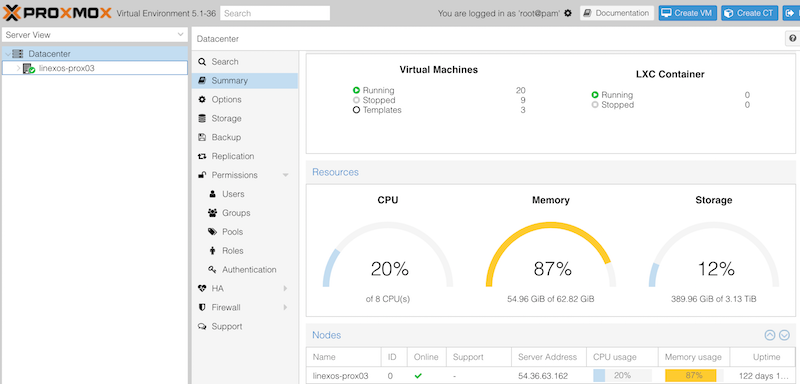
Son installation est relativement simple puisqu'une image ISO est fournie, permettant d'automatiser l'ensemble des opérations.
Dans notre infrastructure, Proxmox supportera l'ensemble des systèmes virtualisés, et sera installé sur un serveur Physique disposant de suffisamment de ressources CPU, Mémoire et Disque.
Nginx
Nginx (prononcez Engine X) est un serveur HTTP et Reverse Proxy, également capable d'agir comme reverse proxy TCP. Sa particularité est d'être asynchrone par opposition aux serveurs synchrones où chaque requête est traitée par un processus dédié.
Dans notre infrastructure, Nginx sera utilisé comme gateway pour recevoir et diriger les requêtes http(s) en provenance de l'extérieur. Son rôle sera de router les requêtes vers les bons services en fonction des URI demandées.
À noter que nginx n'est pas indispensable, et qu'il est tout à fait possible d'utiliser directement les "routeurs" mis à disposition par openshift. Il est cependant intéressant de mettre en place un loadbalancer comme nginx en amont, afin de pouvoir gérer du contenu statique, des pages d'indispo, voire des règles spécifiques.
OpenShift
OpenShift est le PAAS (Plateform As A Service) de la société Red Hat. Cette solution s'appuie sur Kubernetes pour l'orchestration et la gestion des conteneurs, en ajoutant les fonctionnalités suivantes :
- Développement rapide d'application
- Déploiement d'application simplifié
- Scalabilité
- Automatisation (Construction d'application, déploiement, routage)
- Plateforme multi-tenants (Gestion de projets, de droits, etc.)
- Une interface Web pour le déploiement et le monitoring
Son installation est également simplifiée par l'utilisation d'Ansible, ce qui assure une meilleure maintenabilité (souvent compliqué sur ce type de plateforme...).
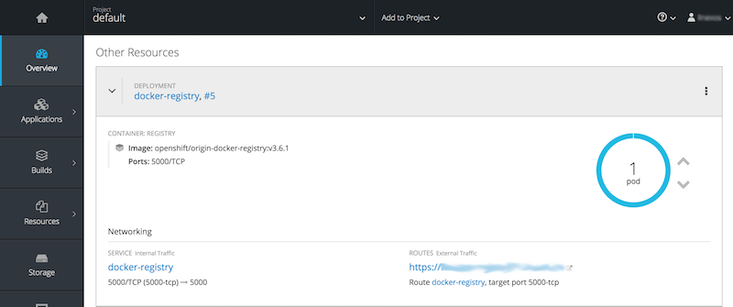
Dans notre infrastructure, OpenShift va nous permettre de déployer et gérer les conteneurs, d'assurer une bonne répartition de charge entre les nœuds, et de simplifier au maximum le déploiement d'application jusqu'à leur mise en production.
Dockers
Docker permet de construire et gérer des applications sous forme de conteneurs isolés, en mettant à disposition une API de haut niveau. Cette technologie permet aux développeurs de s'affranchir de l'architecture sur laquelle sera déployée l'application, tout en structurant les applications, et en fiabilisant leurs futurs déploiements.
Cette technologie répond également à l'agilité nécessaire dans l'ère du tout digital. Il est donc possible de développer une application depuis son poste en construisant dès le début cette application dans un Docker, puis une fois validée, cette application peut être mise en production en quelques clics via OpenShift !
Dans notre infrastructure, Docker sera orchestré par OpenShift, via Kubernetes. Nos développeurs pourront coder et tester les applications directement depuis leur poste, avant de les déployer sur notre infrastructure.
Persistent Storage
Pour ceux qui connaissent Docker, sans créer de Volumes, et de Persistent Storage, les données ne seront pas conservées lors de la reconstruction du conteneur, ou lorsque ce dernier changera de nœud OpenShift.
Il est donc indispensable de mettre à disposition des conteneurs du Stockage Persistent. Cette obligation, vue comme une contrainte de prime abord, s'avère finalement être une bonne chose pour tout le monde !
Fini les applications qui écrivent des données n'importe où, et surtout on pense maintenant les applications différemments, en sérialisant les données, et en réfléchissant API et Webservices. Au final, tout le monde s'y retrouve !
Dans notre cas, et pour ne pas trop compliquer cet article, nous allons prendre l'exemple de trois types de stockage de données :
-
Données liées à la configuration et aux contenus statiques en s'appuyant sur NFS (Network File System)
-
Données liées à du stockage de données type documents / index en s'appuyant sur la suite Elastic
-
Données relationnelles en utilisant un SGBD, ici PostgreSQL
Les conteneurs auront accès à ces Persistent Storage via des variables d'environnements positionnées au moment de leur démarrage. Ces variables seront donc soit renseignées sur la ligne de commande permettant la création d'un conteneur, soit directement via le formulaire de création OpenShift. Ce qui, encore une fois, permet une grande souplesse et une simplification maximum, puisque la configuration des datastores devient uniforme quelque soit l'application !
Tools
Cette brique est indispensable pour la production et l'exploitation. C'est via cette brique que l'on pourra surveiller efficacement les ressources et les différentes charges, puisque, rappelons-le, l'infrastructure présentée doit être capable de mettre à disposition des centaines d'applications...
cAdvisor est incontournable sur ce type de plateforme. Fonctionnant lui-même dans un conteneur, cet agent surveille et récupère les données de consommation des ressources et des performances comme le processeur, la mémoire, ainsi que l'utilisation disque et réseau des conteneurs de chaque nœud. Il est également utilisé pour gérer l'auto-scalling de Kubernetes.
Dans notre cas, nous allons utiliser cAdvisor pour récolter de manière aisée et intégrée l'ensemble des métriques utiles : CPU, Mémoire, etc. cAdvisor mettant à disposition ces résultats à travers une API Rest, nous pourrons utiliser un outil de supervision plus global pour centraliser ces métriques.
Shinken (Enterprise)
Cette brique va nous servir à surveiller l'ensemble des composants mis en place, que ce soit l'hyperviseur, les machines virtuelles, ainsi que les applications. Les conteneurs seront eux aussi supervisés via les API de cAdvisor.
Shinken, dans sa version Community comme Enterprise, repose sur un système de plugin Open Source, ce qui le rend polyvalent et flexible.
Pour surveiller les applications, qui reposeront probablement sur différents tenants, il sera possible de créer des règles métiers permettant ainsi de surveiller et valider l'ensemble de la chaîne composant une application. Voir l'article http://blog.linexos.fr/surveillez-vos-applications/ pour plus de détails sur le sujet.
Dans notre cas, Shinken va nous servir à surveiller l'état des serveurs (physiques et virtuels), l'état des ressources, et également l'état des applications et composants (Stack Elastic, etc.).
Grafana
Grafana permet la mise en forme et la visualisation de données types métriques, en provenance de bases temporelles (Graphite, InfluxDB, Elasticsearch, etc.), sous forme de tableaux de bords.
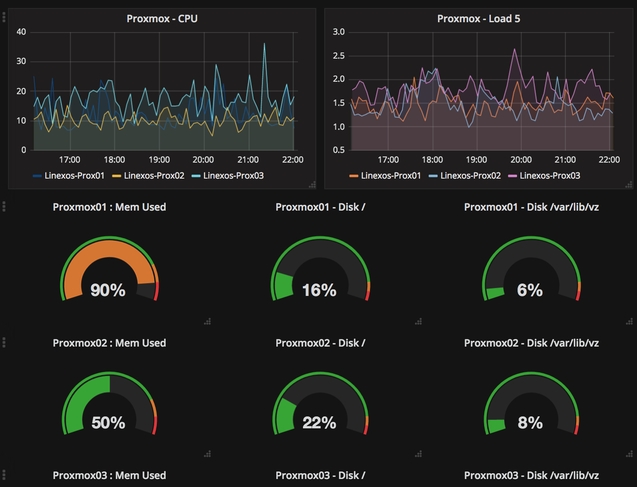
Dans notre cas, Grafana sera utilisé pour afficher sur un même tableau de bords des métriques en provenance de Graphite (alimenté par Shinken). Il sera possible de surveiller l'ensemble des nœuds et de comparer l'utilisation des ressources.
Les briques sont posées !
Maintenant que l'ensemble des briques sont posées, et que les choix technologiques sont faits, il ne reste plus qu'à installer et configurer les différents composants (ce que nous ne détaillerons pas ici...).
L'infrastructure OpenShift sera composée des éléments suivants :
- un master (orchestration, API)
- deux nœuds "applications"
- deux nœuds "infra"
Cette configuration est le minimum recommandé, il est bien sûr possible de déployer plus de nœuds et d'ajouter de la redondance sur le master. Chacun de ces composants sera déployé sur des machines virtuelles séparées.
Les nœuds "applications" seront utilisés pour déployer les conteneurs de production, tandis que les nœuds "infra" assureront le fonctionnement des routeurs (haproxy), des Registry (Docker), et tous les outils utiles à l'exploitation.
Cette configuration assure une répartition de charge, de la haute disposinibilité, et facilitera la scalabilité plus tard si nécessaire.
Pour la partie "Datastore", nous mettrons en place un cluster Elastic, un cluster PostgreSQL, et un serveurs NFS (qui peut également être mis en cluster avec un filesystem type GlusterFS par exemple).
Shinken (Enterprise) sera installé sur une VM dédiée. Grafana pourra être installé sur le même serveur. cAdvisor sera déployé sous forme de conteneur Docker depuis OpenShift.
Enfin, notre reverse proxy "frontal" sera installé sur une VM dédiée. Pour fiabiliser cette brique, il est possible d'installer deux serveurs, et utiliser du RoundRobin DNS.
Configuration
Gestion du DNS
Afin de simplifier les futurs opérations, un domaine sera dédié à notre infrastructure. Nous allons donc créé une entrée de type A :
*.linexos-dev.fr -> X.X.X.X (IP du Reverse Proxy Nginx)
Cette entrée nous permettra de ne plus avoir à gérer le DNS par la suite, et de déployer des applications rapidement, dans l'esprit DevOps !
Reverse Proxy
Une fois l'ensemble des composants installé, il est nécessaire d'exposer notre console OpenShift afin d'y accéder depuis l'extérieur, en ajoutant la configuration nécessaire sur Nginx.
On démarre ?
Notre infrastructure est installée et opérationnelle, il est maintenant possible de se connecter à l'interface et déployer notre première application !
Lors de la connexion, la page d'accueil affiche la liste des projets. Nous allons donc commencer par créer notre premier projet, et déployer nos premiers conteneurs depuis la console Web OpenShift.
Quid de la scalabilité ?
Notre infrastructure est basée sur un hyperviseur ProxMox, autorisant la gestion de cluster, ce qui permet d'étendre notre hyperviseur sur plusieurs serveurs physiques, en ajoutant donc une répartition de charge, ainsi que de la haute disponibilité. On pourra par exemple mettre en place l'infrastructure suivante :
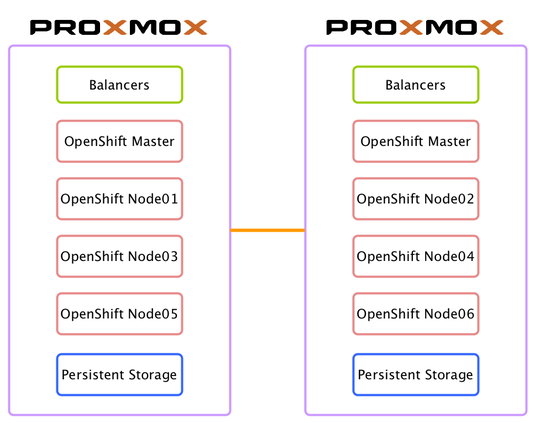
Il sera donc possible d'augmenter facilement le nombre de nœuds en fonction du nombre d'application déployées.
La scalabilité des applications peut être gérée directement depuis OpenShift. Il est ainsi possible de démarrer plusieurs instances (plusieurs conteneurs) pour une application, ce qui permet de répartir la charge et de fiabiliser l'application.
Conclusion
La première partie de cette série consacrée à OpenShift est terminée.
Dans le prochain article, nous détaillerons le déploiement d'une application en partant de la construction de l'image Docker jusqu'à sa mise en production.
